


Mining Minds: The Genius of the Modern Search Box
Exploring How Search Boxes Have Redefined Information Gathering and Their Next Evolution in AI Products

The search box is a tool we all use, but how much do we really understand it? This unassuming interface has unlocked the world's knowledge, capturing trillions of questions each year and transforming how we find information. As it evolves into AI-powered conversational chatboxes, our interactions become more direct and personal.
This post delves into the history and evolution of the search box, the technology driving it, and the ethical implications of its advancements. By shedding light on what happens behind the scenes, we explore why understanding this seemingly simple tool is more important than ever in our digital lives today.
Sections Covered:
The Search Box Phenomenon
Origins and Evolution
The Power Behind the Box
Design, Functionality, and User Considerations
Bias, Trust, and the Future of AI Search Tools
1. The Search Box Phenomenon
A 2017 article in the Economist proclaimed: The world’s most valuable resource is no longer oil, but data. When you browse the internet, companies can track your entire journey— from the link you came from, to your flow across pages, time spent on each page, mouse movements, and even incomplete information you type but don’t submit. Every session leaves a vast amount of data behind. This data tracking is primarily to enhance sales, revenue, and user interaction insights. If tiny data points are highly valued for making inferences, the data we actively input into platforms is worth much more.
The search box is a simple interface: the user inputs some information (even a question is information), and the backend algorithms attempt to determine what the user wants to get value from the service. The data Google gathers from its search box has enabled it to create powerful products across various sectors, notably Google Trends. The visibility into searches impacts society and commerce, allowing for more targeted content and insights into community interests. The rapid pace of technological advancement often overshadows the depth of these insights.
When we enter information into a search box, it's not just for our own use; it becomes a data point that generates inferences about us and others like us. This input helps predict future behaviors and contributes to a vast data broking market. Shoshana Zuboff explains that this practice, known as surveillance capitalism, involves capturing and selling our data to predict behaviors, a process that has expanded well beyond its origins.
Despite agreeing to privacy policies, many people aren’t aware of how much their search queries contribute to broader data analytics. Searching for information is the dominant internet use across all age groups. As of 2023, about 68% of online experiences start with a search engine, handling over 2.2 trillion queries annually.

This immense amount of data is invaluable for data mining, the process of analyzing large datasets to uncover patterns, trends, and insights. Data mining uses sophisticated algorithms and statistical methods to identify relationships within the data that are not immediately obvious. Understanding search behavior is crucial for effective data mining. For example, research from Semrush determined that on desktops, users change their queries 17.9% of the time, whereas on mobile, they do so 29.3% of the time. These variations highlight how different contexts, like device type, influence search behavior.
With the rise of chatbots and conversational AI, the nature of data input is changing. Chatbots inherently generate more queries and capture more detailed interactions using natural language, providing a higher resolution of human thought processes. This richer data allows for even deeper insights and more precise predictions, further enhancing the power of data mining.
Going back to the mining analogy, a single search is like one swing of a pickaxe on the rock of our thoughts. A conversation with a chatbot, however, is like multiple strikes at that rock. When you scale this up to 2.2 trillion swings, each multiplied by the extra effort of conversational queries, you need a lot more pickaxes to handle the increased volume. This escalating demand for powerful processing drives the skyrocketing valuations of companies like NVIDIA, which manufacture the metaphorical pickaxes. NVIDIA briefly became the most valuable company in the world by providing the advanced computing power needed to process all this data through their GPU products.
The evolution of data extraction mirrors technological advancements in oil extraction—from hand-operated winches to massive offshore rigs. Similarly, the keyword-focused search box, popularized by Google, has evolved from a basic input tool to a sophisticated multimodal interface, accommodating voice, image, and even video inputs in today's products — Allowing for richer volumes of input data to be provided by users.
The ability to train on the data is mirrored by the ability to get the inputs, whilst before text was the primary resource to mine, now these companies can gather video, image, and human voice, with the ability to use the unique characteristics of each type — we have seen deepfakes of celebrities showing that already, convicing fake videos can be made from already publicly available information of one individual. So as the data of each types grows larger inferences can be made from these new multimodal treasure troves of data.
From my own experiences working in product development, onboarding users is one of the most challenging aspects of introducing a new product or feature. Universally known designs, such as the search box, are powerful because they offer an unparalleled level of intuitiveness and ease of adoption. New technologies that leverage familiar interfaces can allow users seamlessly transition and explore the new capabilities with minimal friction. It’s for this reason, that ChatGPT was one of the fastest growing products in history — Reaching 100 million users within 2 months of the public release of their GPT-3 Model.
2. Origins and Evolution
The search box as a user interface component was first implemented in Archie in 1990, the first-ever search engine. Archie was created one year before the World Wide Web and could only search for file names on specific servers using the File Transfer Protocol (FTP). Since there weren't many results to sift through, there was no need to organize or index them. This made the search process quite simple compared to today's standards.
#/media/File:Archie_search_engine.png){kind=link}
After Archie, the next few years saw iterative developments in the scope of searchable content on the web. New search engines began to appear, each improving on the previous one's capabilities and expanding the types of content that could be searched. However, the game-changing innovation came with the launch of Google.
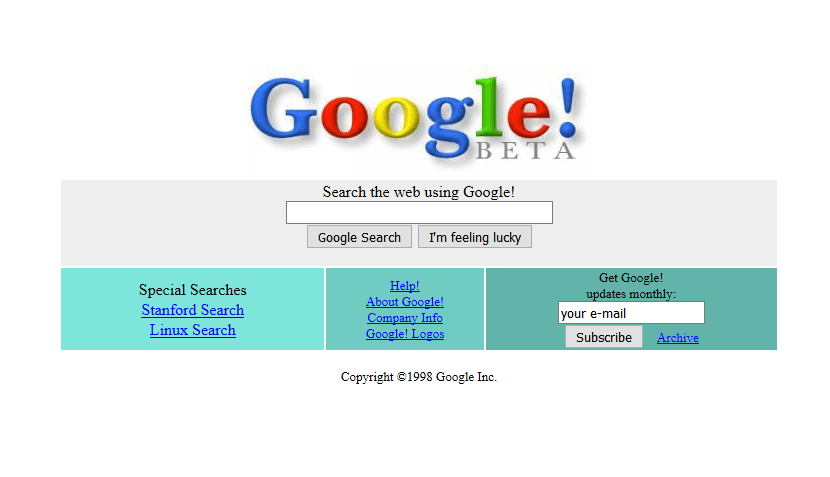
Google, founded in 1998, revolutionized the search engine landscape with its PageRank algorithm. PageRank evaluated the importance of web pages based on the number and quality of links pointing to them, significantly improving the relevance and accuracy of search results. Google's minimalist search box and clean interface also set a new standard for user experience.
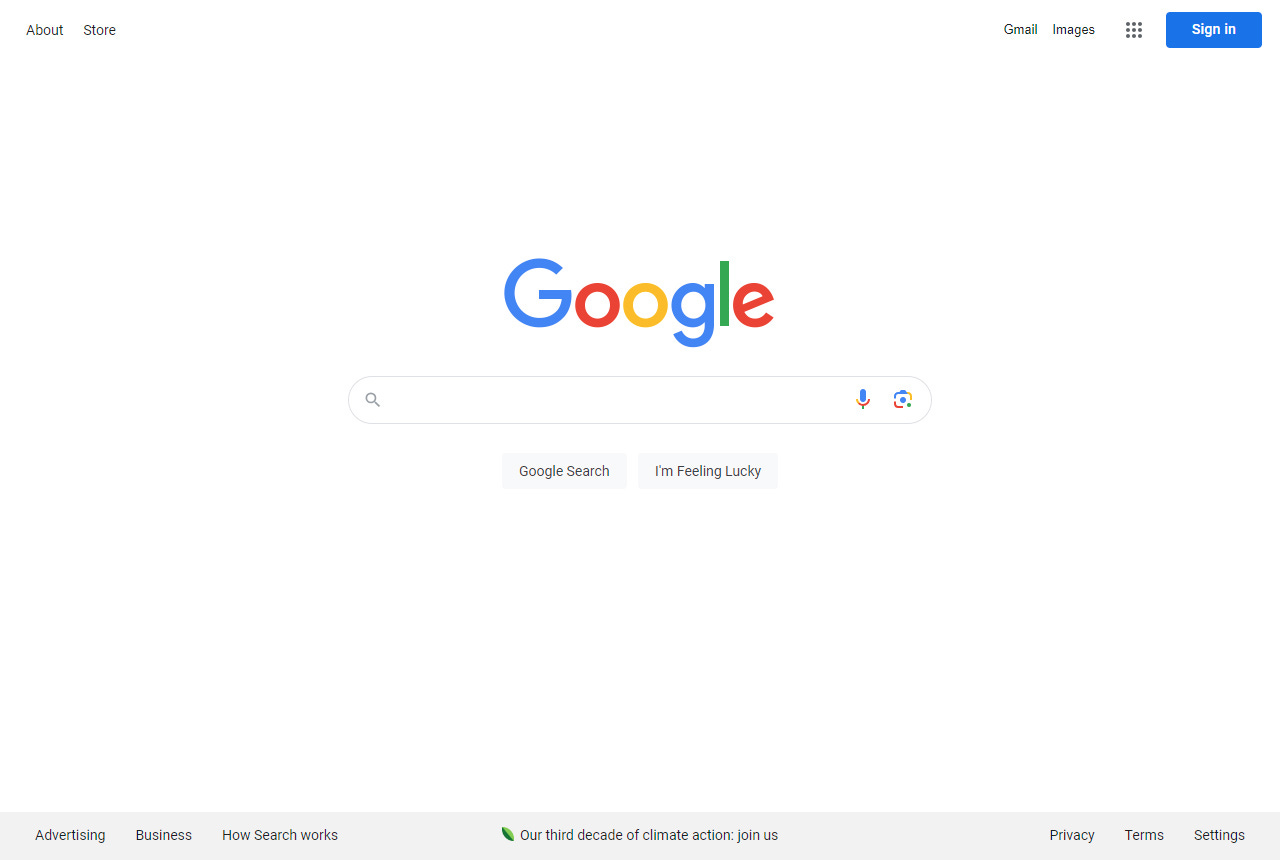
Notably, the design of Google’s homepage from 1998 remains fundamentally the same in 2024. The 'one box' search interface has stood the test of time, much like the push-button simplicity of a Polaroid camera. This design makes it easy for users to find specific information in an ocean of data, just as a Polaroid camera made photography accessible to everyone with a single click.
The search box remains the preferred design for the next wave of search technologies, including tools like OpenAI's ChatGPT products. While these chatboxes resemble traditional search boxes, they have evolved significantly. They now combine simplicity with advanced capabilities, such as remembering context and understanding natural language, transforming simple searches into richer, more intuitive conversations. These chatboxes are user-friendly and versatile, enhanced by multimodality—enabling interactions through voice, image, or even video—providing value across various needs.
In the ChatGPT interface, user onboarding is done through clickable widgets with simple, low-context examples that quickly show new users what it can do. The intention is to encourage users to explore the platform's capabilities. These examples are designed to spark imagination and inspire users to think about different types of questions to ask. Unlike the conventional method of phrasing a question, clicking through top links, and adjusting the query, this conversational approach allows users to iteratively refine their questions and improve the context in a continuous, lower-friction way.
The study Large Language Models vs. Search Engines by Kevin Matthe Caramancion reveals that users prefer search engines for straightforward, fact-based queries and favor large language models (LLMs) for tasks needing natural language processing and personalized responses. It becomes clear how LLMs can parse conversational and vague questions into helpful outputs. Currently, most of these AI-based models remain free of advertisements—one of the aspects that has historically damaged the usefulness of search engines.
This issue was a major point of contention for Google in its early days, as detailed in Steven Levy's book In the Plex, where the company struggled to balance monetization with user experience before gradually becoming more commercialized over time. The research highlights the potential for integrating both technologies to create a more efficient and holistic information retrieval experience.
3. The Power Behind the Box
When we use Google to search for information, a complex process is set into motion behind the scenes. Understanding this process and comparing it to how generative LLM models retrieve and generate output reveals the power and limitations of each approach.
The conventional search information retrieval model as used by Google consists of four stages:
Crawling: Google uses web crawlers (like Googlebot) to explore the web, find new and updated pages, and collect data from them. These crawlers follow links from page to page, building a massive index of the internet's content.
Indexing: The collected data is then indexed, which means Google organizes the information based on keywords, content, and other relevant information, similar to creating a giant library catalog of the internet.
Ranking: When you perform a search, Google’s algorithms analyze various factors such as keywords, content quality, page authority, and user engagement to determine the relevance of indexed pages to your query.
Serving Results: oogle displays the search results on the search engine results page (SERP) in order of relevance and quality, based on the algorithms' evaluation. The SERP may include various types of content such as web pages, images, videos, and news articles.
In contrast, the LLM information retrieval model used by ChatGPT follows a different approach:
Training: LLMs are trained on a vast corpus of text data using machine learning techniques. This involves exposing the model to diverse text sources (books, articles, websites) so it can learn language patterns, facts, and contextual understanding. The text data is broken down into smaller units called tokens, which can be words or subwords, allowing the model to grasp the structure and meaning of the language.
Inference: When ‘searching’ or ‘conversing’ with the LLM, the model processes the input based on its training data and generates a response. It doesn't search the web in real-time but relies on the patterns and information it has learned from the tokens during training.
Response Generation: The model uses the context of the query and its learned knowledge to generate a coherent and relevant response. It constructs the answer token by token, predicting the next token based on the previous ones and the overall context, ensuring the response is fluent and contextually appropriate.
The information we input into these systems significantly affects their feedback loops and overall performance. In Google's model, user interactions such as clicks, dwell time, and query reformulations provide continuous feedback. This feedback helps refine search algorithms, improve ranking accuracy, and enhance the relevance of search results. Each query contributes to a vast dataset that trains and updates the algorithms, creating a dynamic and responsive search experience.
In the case of LLMs like ChatGPT, user interactions also play a crucial role in the feedback loop. When users engage with the chatbox, their queries and the context of those queries help fine-tune the model. Feedback mechanisms, such as user ratings of responses, allow developers to identify and correct errors, biases, and gaps in the model’s knowledge. This iterative process helps the AI become more accurate and useful over time. However, because LLMs generate responses based on training data rather than real-time searches, their ability to stay current relies heavily on regular updates and retraining with new data.
These different technologies can create unique challenges, especially when combining AI with traditional search models. For example, Google’s AI Overviews feature has produced inaccurate results, like geologists supposedly recommending that humans eat one rock per day. These errors show the difficulties and potential issues of mixing AI-generated content with regular search engines. As we keep integrating AI into everyday tools, solving these problems will be crucial for improving user experience and building trust in these systems.
4. Design, Functionality, and User Considerations
When we use a search box or multimodal input, it’s easy to overlook the complexity behind these tools and how our interactions affect them. Modern software aims to make these tools as simple and user-friendly as possible. This simplicity attracts more users, which in turn provides more data to improve and develop new features. Understanding the design and functionality of these systems is critical for us to become more informed users, aware of the data we generate and how it’s used.
One fascinating aspect of search box design is how it subtly guides users. The way a search box suggests queries can shape the data that companies collect and analyze. For example, autocomplete suggestions can steer users toward popular or trending topics, generating valuable data on user interests and behavior while also helping the user. The interesting part is the asymmetry:
Consider searching for top songs around Christmas. You get the list of top songs, meeting your goal, but the provider gains much more. They can analyze the timing and frequency of Christmas song searches to optimize advertising strategies for the future. If many people search for Christmas songs on December 21st, this data can help companies decide when to start their holiday marketing campaigns. This kind of data analysis isn't inherently good or bad, but it highlights the one-sidedness of the context—users get answers, while providers gain insights that can shape future user behavior and marketing strategies.
Additionally, in a traditional Google search, you see webpage titles, sources, and links, but in LLM-generated responses, these elements are often tokenized and hidden due to abstraction. Even if you explicitly ask for them, they are generated in a probabilistic manner, which can result in hallucinations, as seen in the infamous Canadian lawyer case. In this regard, generative AI models function like advanced autocomplete tools: they predict the next word or sequence based on observed patterns. Their goal is to generate plausible content, and not to verify its accuracy. This means any truth in their outputs is ultimately coincidental. This represents a significant shift.
While these models can provide more neutral responses that avoid bias towards any single source, they also remove the user's ability to make informed decisions by obscuring the logic and intent behind the source information. This abstraction challenges users to develop new skills to critically evaluate AI-generated content, highlighting the need for increased awareness and education on these technologies.
Key User Considerations:
Think from the Company’s View: Consider why features are implemented in certain ways. Think about the product’s context, the designers’ background, and the company’s history. Understanding the reasons behind an interface helps you see its purpose.
Remember Your Goal: Keep in mind why you started your search and what you want to achieve. This focus helps you avoid distractions and stay aligned with your goals. While detours can sometimes be useful, staying on track ensures effective use of technology.
Be Aware of Your Data Input: Every query, voice input, or chatbox interaction provides data. This data helps improve the service but also feeds into larger datasets used to refine algorithms and products.
Multimodal Inputs: Using voice, images, and videos makes the data you provide richer and more detailed. This can improve response relevance but also means sharing more about your context and environment. It’s important to balance convenience and privacy.
Autocomplete and Suggestions: These features enhance user experience by predicting your searches. However, they also guide your behavior, directing attention to certain topics. While helpful, these nudges subtly shape your actions.
A good example to illustrate these considerations is the design of OpenAI's user-created no-code GPTs marketplace. This marketplace acts as a testing ground, allowing users to explore and rate different specific use cases for LLMs. By crowdsourcing ideas and feedback, OpenAI can identify which applications are most valuable and how context is used effectively, essentially creating MVPs (minimum viable products) for various specific use cases with minimal expenditure of their own resources. While these GPTs may be more helpful for some tasks, any user could use the same model with custom instructions. However, the marketplace allows community ranking, providing systematic data on which directions are most useful, guiding future product development.
5. Bias, Trust, and the Future of AI Search Tools
The search box has evolved; it now talks back. It's no longer just an empty box where you put your thoughts—it has the ability to persuade you directly, often without clear sources or attribution. This shift raises important ethical questions.
In testing, GPT-3 was used to generate articles using a title and subtitle, before testing with humans to see if they could determine whether the text was human or AI-written. The size of the model, measured by the number of parameters, significantly impacts its performance. With the smallest version, which has 125 million parameters, people correctly identified its text 76% of the time, making it easier to recognize as AI-generated. In contrast, with 175 billion parameters, the AI's text is nearly indistinguishable from human writing, with people correctly identifying it only 52% of the time, which is close to random guessing. This demonstrates that increasing the number of parameters makes AI-generated text significantly harder to distinguish from human-written text.
A great post by
, Why Your AI Assistant Is Probably Sweet Talking You, highlights recent research by Anthropic, revealing that state-of-the-art AI models exhibit sycophantic behavior, or tendencies to sweet-talk. This behavior is likely caused by the methods used to direct model behavior, specifically through reinforcement learning with human feedback (RLHF). This underscores the importance of critical thinking when interacting with these technologies, reminding us to be cautious and discerning.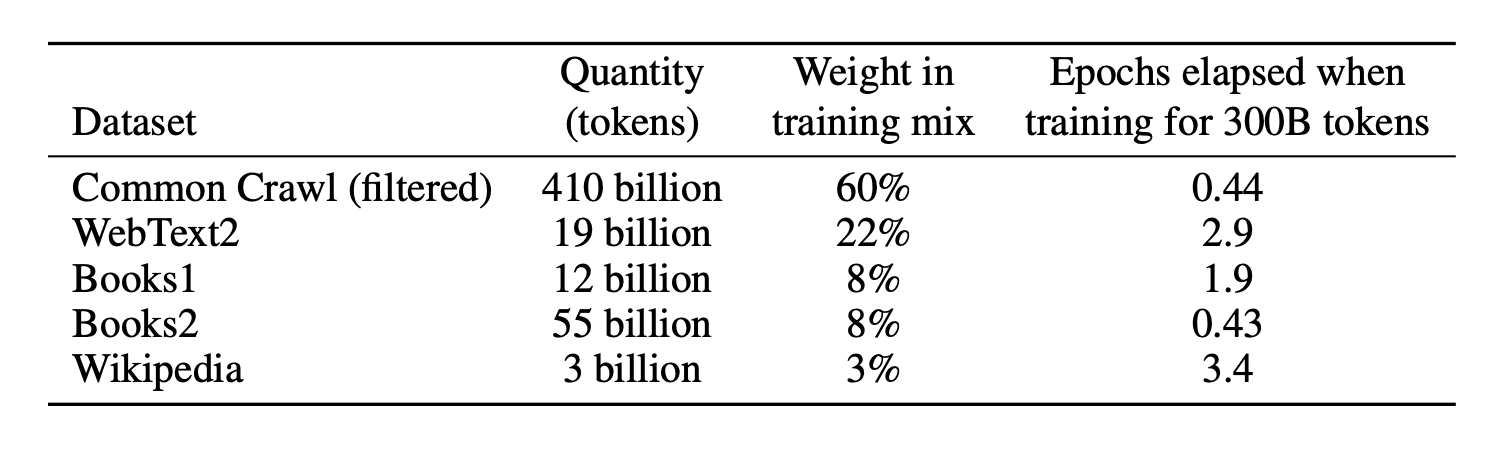
The datasets used to train many of the leading LLM models today are derived from openly accessible sources on the internet. The majority of data comes from a filtered Common Crawl dataset, which includes vast quantities of information from a variety of websites. This collection process encompasses data from forums, social media platforms, news sites, blogs, and more. While this approach provides a broad and diverse dataset, it also introduces several types of potential errors and challenges. OpenAI has acknowledged these difficulties and the challenges they pose for future development.
The act of ranking higher in search indexing gave rise to the multibillion-dollar industry of Search Engine Optimization (SEO). Similarly, we are likely to see the emergence of Large Language Model Optimization (LLMO). Given the known sources for training, it is plausible, though difficult to measure, that these sources and information about specific weightings could be targeted for manipulation by individuals, corporations, or states to align with their private interests. Since LLM outputs are probabilistically determined on a token basis and fundamentally disconnected from any direct individual source or reference, users will have less control over determining the quality and understanding of the data they are shown.
It is important for us to remain skeptical when working with any AI model. Experience, Expertise, Authority, and Trust are the cornerstones of Google’s quality rating guidelines for SEO, making it the top search engine. ChatGPT and other chatbot-like search products are not yet able to validate information or retrain against incoming data concurrently. Therefore, while these AI models offer advanced capabilities, they also require careful scrutiny and critical thinking from their users.
Google pays around $20 billion a year to Apple to be the default search engine on Safari. It's reasonable to assume that being natively integrated into Siri would be worth even more. At WWDC24, Apple unveiled its proprietary AI. However, when the AI reaches the limits of its ability, users can seamlessly forward their queries to ChatGPT within iOS at no additional cost. This strong relationship with OpenAI may benefit Apple in the long run, as it's unlikely Apple will catch up due to its focus on privacy and not collecting data.
The asymmetry in this relationship—open-sourcing training data while privatizing results—raises concerns, as highlighted by Elon Musk regarding the ‘Open’ in OpenAI. Despite the minimal costs associated with processing the data received, the value derived from this data far outweighs these costs, akin to the concept of data being the new oil. This dynamic has already played out with the traditional search box, as evidenced by Google's evolution, where the significant value of user data has led to immense profits and market dominance.
Algorithmic decisions have long been used to aid our search for information and enhance decision-making processes, but they can also be manipulated. With conversational search becoming more powerful, a greater level of trust is required. Users must be aware of potential biases, incentives, and commercial interests embedded in these tools. It is important to remain skeptical of any output and reflective on each interaction with any 'box' they interact with online. Maintaining a critical and informed perspective will be essential in ensuring these tools serve to enhance our knowledge rather than distort it on an individual and societal level.
Thanks for reading!—Found value in this? Three ways to help:
Like, Comment, and Share—Help increase the reach of these ideas
Subscribe for free—Join our community of makers
Become a paid subscriber—Support this creative journey
Keep Iterating,
—Rohan

I’ve never before felt like I’ve taken a simple element so for granted.
Fascinating, was slightly hoping you would have covered the Perplexity in the media story in this. The role of Generative AI and search bots is an issue since OpenAI is gearing to launch their own web-search product.