As social networks collect vast amounts of personal data, they assure us that our privacy is protected through anonymization. But how reliable are these promises? Dive into the fascinating world of data anonymization, uncover its strengths and weaknesses, and find out if your personal information is truly safe.
Sections Covered:
The Transformation of Social Networks and User Data
Techniques for Anonymizing Social Network Data
How Social Networks Use Anonymized Data
De-Anonymization: The Reality Behind Anonymized Data
The Future of Data Anonymization in Social Networks
Product Artistry is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
1. The Transformation of Social Networks and User Data
Social networks have evolved from simple, unrecorded human interactions, to partially documented exchanges, and now to today's complex and entirely closed digital platforms. Historically, information was scattered and difficult to access, making it much harder to misuse or analyze. The barriers to data theft or analysis were significantly higher due to the limited availability and concentrated nature of information and resources. Despite these limitations, social data has driven significant advancements in fields such as epidemiology, sociology, and economics. Researchers and analysts have used this data to gain valuable insights, driving progress and innovation with substantial oversight and regulation due to its national and international importance.
Today, the landscape has drastically changed. Social networks, now operated by private companies, store vast amounts of personal data in massive repositories. This concentration of data allows for unprecedented analysis and user engagement optimization, but it also introduces significant risks. Such extensive data collections are more vulnerable to breaches and misuse, as the same computational power that built these networks can also be used to unravel them, exposing personal information and compromising user privacy.
Using these platforms generates a vast amount of data that is both insightful and potentially intrusive. Whether engaging in conversations, sharing content, or just scrolling through videos, users leave behind a digital trail. User data on social networks can be categorized into six main types:
Personally Identifiable Information (PII): Information that can be used to identify individuals, such as names, email addresses, phone numbers, and profile pictures.
Behavioral Data: User interactions, preferences, likes, shares, comments, and engagement metrics.
Location Data: GPS data, check-ins, and location tags indicating user locations.
Content Data: Text, images, videos, and other multimedia content generated and shared by users.
Metadata: Information about other data, such as timestamps, geolocation tags, device information, and file properties.
Contact Data: Lists of friends, followers, connections, and social network information revealing relationships and social structures.
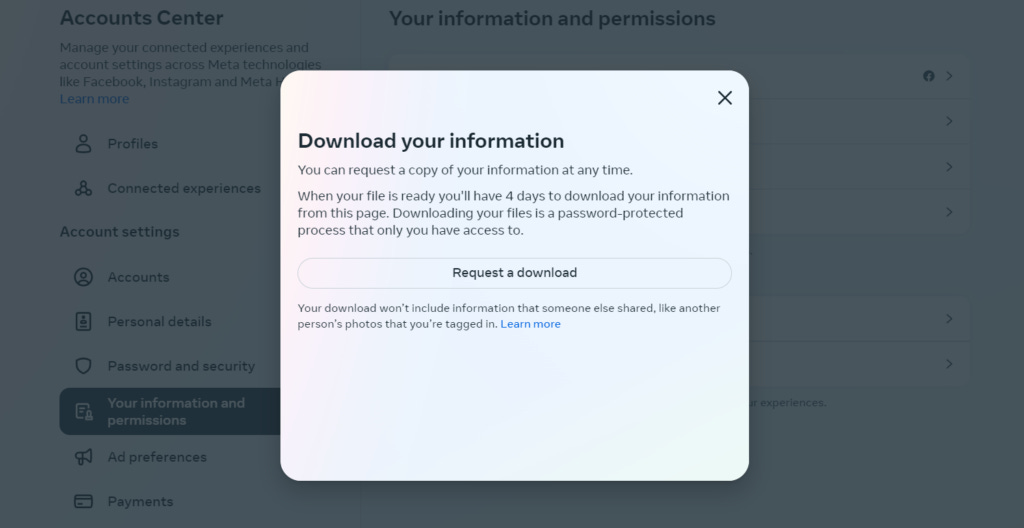
If you're curious to see exactly how much data these platforms collect, try requesting to download your data (often found in the account settings area of a platform). You might be surprised by the file size—it's often much larger than expected, showing just how much information they gather from your activities.
To manage these vast data repositories while protecting user privacy, social networks anonymize data. This process aims to retain the value of data for analysis and innovation while mitigating the risks of breaches and misuse, ensuring that users' personal information remains protected even as it drives the digital economy.
To protect personal information while still enabling valuable data analysis, social networks and other organizations employ a variety of anonymization techniques. These methods, shaped by technical standards and legal regulations like GDPR in Europe or CCPA in California, help ensure that data remains useful without compromising individual privacy. Here are some of the key techniques used:
Data Masking: Replacing sensitive information with fictitious data while maintaining the structure.
Example: User names might be replaced with generic labels like "User1" or "User2."
Pseudonymization: Substituting private identifiers with pseudonyms or unique codes.
Example: A repository of tweets might have usernames replaced with codes like "User_A" and "User_B."
Aggregation: Combining data from multiple users into summary statistics, reducing the likelihood of identifying individuals.
Example: Summarizing user age data by grouping them into age ranges.
Noise Addition: Injecting random data to obscure individual entries while preserving overall trends.
Example: Adding random variations to user ages to prevent identifying specific individuals.
Differential Privacy: Adding calibrated noise to data to protect individual privacy while keeping overall trends accurate.
Example: Slightly altering ages in a survey so individual ages are obscured, but the average age remains accurate.
Generalization: Replacing specific data points with broader categories.
Example: Converting precise ages into age ranges (e.g., 70+ instead of 81).
By employing these anonymization techniques, social networks aim to balance the need for data-driven insights with the imperative to protect user privacy. Each method provides a different level of protection and utility, and often, multiple techniques are used in combination to enhance data security and compliance with privacy regulations. This ensures that personal details are obscured while maintaining the overall utility of the data for research, marketing, and other purposes.
3. How Social Networks Use Anonymized Data
User data collection and analysis are crucial for social networks to enhance product experience and achieve business objectives. Platforms rely on this data to decide what content to serve, which ads to show, and how to keep users engaged. To comply with privacy regulations, social media companies anonymize this data while still collecting as much as possible to improve their services.
Anonymized user data drives several key functions within social media products:
Product Development: Analyzing anonymized data shows how users interact with the platform, helping developers identify popular features and common issues. This leads to improved user experiences of the product, attracts more users, and increases revenue.
Targeted Advertising: Forming the bulk of revenue for social networks, targeted advertising relies on anonymized user profiles. These profiles help advertisers deliver personalized ads that match user interests. Additionally, anonymized data improves content recommendations, keeping users engaged longer and increasing ad impressions.
Market Research and User Behavior Analysis: Aggregated anonymized data identifies trends and consumer preferences. If data shows a growing interest in a product category in any given customer segment, companies can adjust their marketing strategies and products accordingly. Understanding user behavior through anonymized data helps tailor content and ads to user preferences, promoting loyalty and engagement.
Enhancing Security and Compliance: Analyzing patterns in anonymized data helps detect unusual activities and potential threats, enabling the identification of impersonations, fraud, and other security concerns. It also allows for testing new security measures without compromising user privacy. Compliance with data protection regulations is easier with anonymized data, reducing the risk of exposing sensitive information.
While anonymized data plays a vital role in these areas, it is not without flaws. The process of de-anonymization, where anonymized data is cross-referenced with other data sources to re-identify individuals, poses significant privacy risks. This brings us to the reality behind anonymized data and the challenges it presents.
4. De-Anonymization: The Reality Behind Anonymized Data
A 2009 research paper by Arvind Narayanan and Vitaly Shmatikov, De-anonymizing Social Networks, revealed significant vulnerabilities in anonymized data. They demonstrated that anonymized datasets could often be re-identified by cross-referencing them with auxiliary information. Cross-referencing involves comparing anonymized data with additional, external datasets that contain overlapping attributes. By finding patterns and connections between these datasets, it becomes possible to re-identify individuals within the anonymized dataset. This finding highlighted the limitations of traditional anonymization techniques and the need for more robust data protection measures.
Over the years, several notable events have brought attention to the challenges and risks associated with data privacy in social media. Here are some real-world examples that underscore the vulnerabilities in data anonymization:
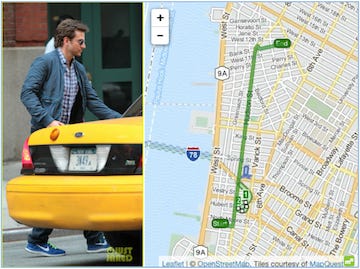
Bradley Cooper’s cab journey uncovered through the retrospective data analysis (Source)
New York City Taxi Rides: An anonymized dataset of 2013 New York City taxi rides was de-anonymized by a blogger that compared it with social media posts and public schedules of celebrities. By examining the pick-up and drop-off locations and times, specific individuals, especially high-profile ones, could be identified. For example, if a celebrity tweeted about attending an event at a particular time, this information could be matched with the taxi data to reveal the celebrity's taxi ride details. This breach of privacy showed how even anonymized transportation data could expose sensitive information about people's movements and activities.
Facebook and Cambridge Analytica: The Facebook and Cambridge Analytica scandal highlighted how data thought to be private could be misused. Cambridge Analytica accessed data from millions of Facebook users and used it to manipulate people for political gain. They targeted individuals with personalized political ads to influence their voting behavior. This incident raised concerns about how personal data in the wrong hands can be exploited for harmful purposes, showing that even data with claimed safeguards can be misused.
Given these examples, it's clear that ensuring true anonymity is challenging. Many people have already been part of large data breaches simply by signing up for platforms they may never have used beyond the initial sign-up. Services like Have I Been Pwned allow individuals to check if their email addresses have been involved in data breaches, illustrating how easily data can be accessed to cross-reference to identify individuals. Data markets that sell breached information further exacerbate this issue, as they provide additional sources of auxiliary data that can be used for de-anonymization. Even with advanced anonymization techniques, there is always a risk that data can be re-identified, especially as de-anonymization methods become more sophisticated.
Understanding these risks is crucial as social networks continue to evolve. While anonymization aims to protect user privacy, it is not an absolute guarantee. This ongoing challenge necessitates continuous improvement in anonymization techniques and greater transparency from social media companies about their data protection practices.
5. The Future of Data Anonymization in Social Networks
In 2019, Narayanan and Shmatikov released an update to their initial paper, Robust de-anonymization of large sparse datasets: a decade later, showing that methods to break anonymization are becoming more advanced. As technology improves, so do the ways to re-identify individuals in anonymized data.
Looking ahead, the challenge is to develop stronger anonymization techniques that can withstand these evolving threats. Social media platforms must prioritize privacy in their designs and implementations. New products should offer users better and more segmented control over what data they share, with defaults set to collect as minimal data as possible. Policymakers, companies, and researchers need to collaborate on strict rules that protect data privacy while enabling useful data analysis.
The rise of consumer-focused AI also makes data privacy more urgent. Richer data from AI interactions, like chat logs, can be de-anonymized more easily. Techniques like sentiment analysis can find patterns in how people type, making it possible to identify them, much like handwriting analysis in detective stories. This makes stronger anonymization even more important. This makes stronger anonymization even more important, especially given the security concerns with market leaders like OpenAI.
’s article, OpenAI: An Insecure AI Lab?, highlights these issues. A key concern is that OpenAI’s technology, integrated via their API into other companies' products, creates global security risks. If many companies rely on OpenAI's API, any weakness can compromise numerous applications and user data worldwide, emphasising that a chain is only as strong as its weakest link. This interconnected risk requires robust security measures and improved anonymization techniques to protect user privacy.
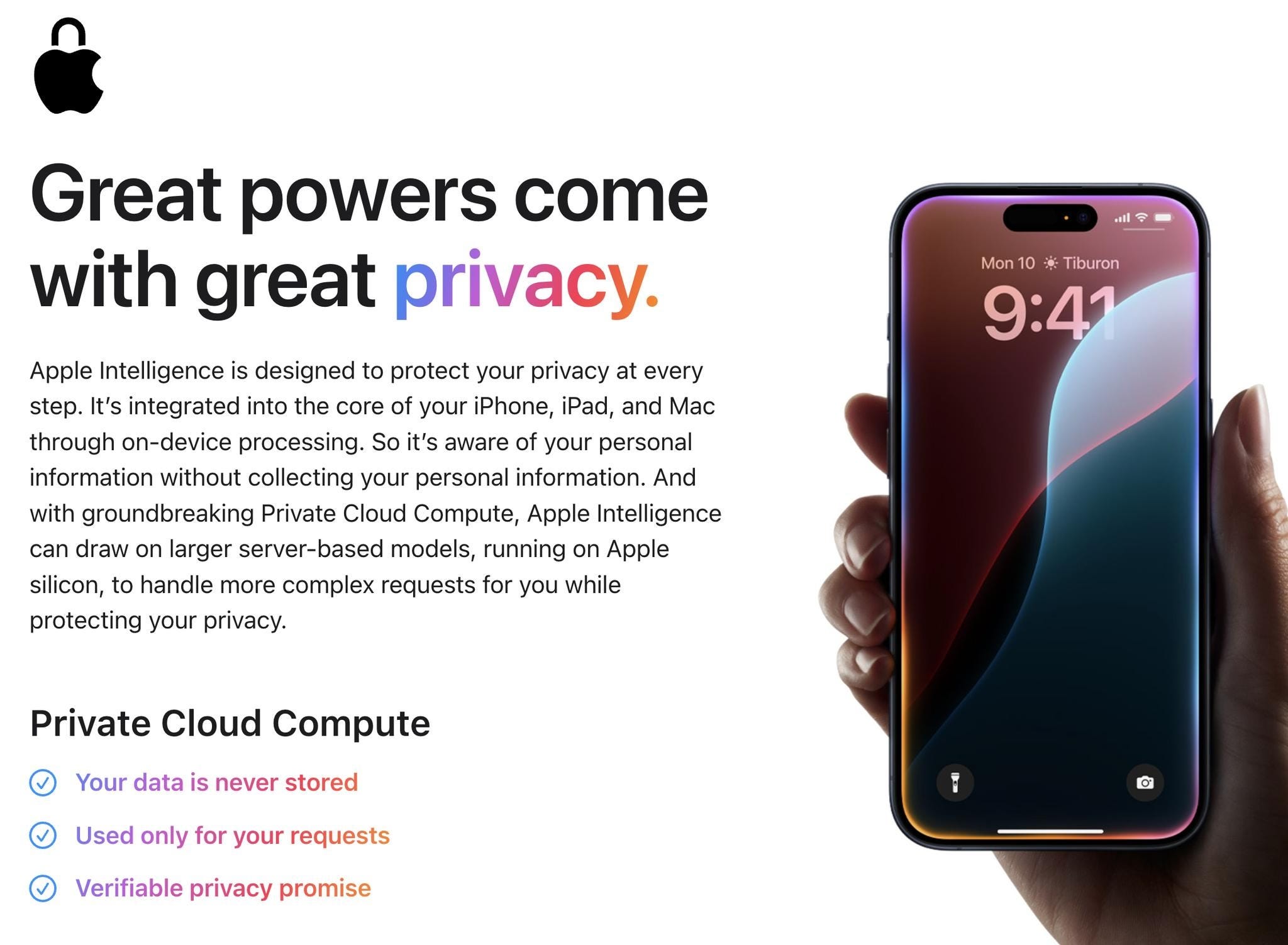
A great step forward would be the use of Federated Learning and On-Device Processing, as Apple plans to do with their proprietary AI integration in their operating systems, leveraging increased computational power and AI-focused hardware. Moving calculations and data processing to users' devices keeps sensitive data on the device, reducing the risk of breaches and unauthorized access. Federated learning allows AI models to be trained on local data across multiple devices without ever transferring raw data to central servers, maintaining privacy while benefiting from collective data insights.
By embracing technological solutions like on-device processing and federated learning, social media companies can better protect user privacy and maintain trust. Ignoring these measures risks losing their competitive edge and user confidence. Strong anonymization practices and advanced privacy technologies, integrated from the start of any product development lifecycle, are crucial for long-term success and user protection. Protecting user data isn't just a legal duty—it's vital to their business models and market trust. As de-anonymization methods advance, failing to act could be devastating for both users and platforms.
Thanks for reading!—Found value in this? Three ways to help:
Like, Comment, and Share—Help increase the reach of these ideas
Subscribe for free—Join our community of makers
Become a paid subscriber—Support this creative journey
It definitely feels like privacy has become an afterthought. Social media platforms should prioritize privacy in designs and implementations. Do you believe it is realistic that they will? I have some doubts, but hope it gets better in the coming years.






It definitely feels like privacy has become an afterthought. Social media platforms should prioritize privacy in designs and implementations. Do you believe it is realistic that they will? I have some doubts, but hope it gets better in the coming years.